股票筛选与排序
1. 前言
在完成因子的选择之后,我们就可以开始构建因子模型了。我们首先来学习一种较为简单的构建因子模型的方法——股票筛选(stock screening)。
2. 股票筛选
股票筛选指的是根据一定的标准将股票池中的股票排序,从而确定哪些股票值得投资,哪些股票不值得投资。
从理论上讲,仅仅依靠股票筛选也可以是一个完整的策略。我们之后会看到,许多经典的策略都是通过简单的股票筛选实现的。
股票筛选有两种基本方法:顺序法(sequential)和同步法(simultaneous),其中顺序法是朴素的排序筛选,而同步法则用到了包括 Z 值在内的统计学方法,相对更为合理。
实际上,可以认为我们之后在4.6.1节所介绍的基本预测模型,就是只包括因子的基本概念分类标准下基本面因子的因子模型。
所以,虽然股票筛选并不是构建投资组合最先进的方法,但可以为我们之后学习因子模型打下基础,同时,其易于实施、不需要掌握大量数学与统计知识以及更加直观的优势,也可以帮我们打下关于量化投资一些基本直觉的基础。
3. 顺序法
3.1 顺序法的含义
在顺序法中,我们根据重要性程度对股票筛选的标准进行排序,先根据最重要的标准对股票池进行筛选,再根据第二重要的标准继续筛选,直到剩下的股票符合所有的选股标准。
3.2 顺序法的理解
顺序法类似闯关游戏。比如某个策略要求 “PE < 15” 且 “ROE > 20%”,那么它会先淘汰所有 P/E > 15 的股票,再在剩下的股票里淘汰 ROE < 20% 的。
但顺序法的问题在于,由于顺序法的规则非常生硬,很容易错杀。例如,可能存在一个 PE 为 14.9 但 ROE 高达 25% 的优质股由于 P/E 卡在 14.9 而被错误淘汰。
3.3 基于著名投资者策略的股票筛选方法
以下是根据不同著名投资者投资方法(或者说风格、哲学)的顺序法表达,需要注意的是,以下的筛选方法经过了大量简化,仅用于表达其个人投资方法及演示顺序法的使用,不能直接作为投资策略。
| 股票大师 | 股票筛选方法 |
|---|---|
| 巴菲特 | Step 1:在 NYSE、NASDAQ 上市的股票中市值排名前 30% 的个股; Step 2:过去 3 年每年的 ROE 均大于 15%; Step 3:每股自由现金流位于数据库的前 30%; Step 4:NPM 高于行业平均水平; Step 5:未来 5 年预期每股自由现金流折现大于当前的交易价格; Step 6:市值增长率高于账面价值增长率。 |
| 德雷曼 | Step 1:在标普 1500 指数中,市值排名前 80% 的个股; Step 2:在标普 1500 指数中,PE 排名后 40% 的个股; Step 3:D/E 小于 1; Step 4:总负债与总资产之比低于其所属行业中位数; Step 5:EPS 的增长率高于标普 1500 指数; Step 6:EPS 的增长率高于其所属行业的中位数; Step 7:当年 EPS 增长率高于上一年 EPS 的增长率; Step 8:下一年预期 EPS 的增长率高于当年预期 EPS 的增长率; Step 9:股利率高于标普 1500 指数的中位数; Step 10:净利润增长率高于 8%。 |
| 德里豪斯 | Step 1:过去 5 年 EPS 的增长率在持续增长; Step 2:当年 EPS 的增长率为正; Step 3:公司公布的盈利高于市场一致盈利预期 10% 之上; Step 4:当年 EPS 的增长率高于行业平均水平; Step 5:股价高于 20 日移动平均线; Step 6:该股票所属行业过去一个季度的收益率高于标普 500 指数; Step 7:20 日的能量潮指标 (OBV) 为正; Step 8:跟踪个股的分析师数量不超过 5 人; Step 9:在纽约证券交易所、美国证券交易所以及纳斯达克上市的股票中市值排名后 85% 的个股。 |
| 费舍 | Step 1:过去 3 年销售收入持续增长; Step 2:过去 3 年销售收入的增长率高于其所属行业的中位数; Step 3:过去 3 年每年的 NPM 均高于其所属行业的中位数; Step 4:PEG 居于行业的后 10%; Step 5:RNDS 高于其所属行业的中位数; Step 6:销售收入的增长率高于研发费用的增长率; Step 7:股利为 0。 |
| 拉科尼沙克 | Step 1:在纽约证券交易所、美国证券交易所以及纳斯达克上市的股票中市值排名前 50% 的个股; Step 2:P/E 低于其所属行业的中位数; Step 3:P/B 低于其所属行业的中位数; Step 4:下一年的预期 EPS 高于当年的预期 EPS; Step 5:在过去一个月内,预期 EPS 至少经历过一次向上修正,并且没有向下修正过; Step 6:股票过去 6 个月的收益率高于标普 500 指数。 |
| 林奇 | Step 1:P/E 低于行业平均水平; Step 2:PEG 小于 1; Step 3:P/E 与 D/P 的比例小于 4; Step 4:当前 P/E 低于过去 5 年的平均 P/E; Step 5:长期负债与权益的比值低于行业平均水平; Step 6:长期负债与权益的比值小于 1; Step 7:每股净现金与每股股价的比值大于 0.2; Step 8:EPS 的增长率在 0 ~ 50%; Step 9:当年内预期买与内部卖出的比例大于 1.5; Step 10:机构投资者持股比例小于 50%; Step 11:市值小于 50 亿美元。 |
| 米勒 | Step 1:市值与自由现金流的比值小于 3; Step 2:当年自由现金流高于上一年自由现金流; Step 3:PEG 小于 1.5; Step 4:GPM 高于行业平均水平; Step 5:ROE 高于行业平均水平; Step 6:过去 5 年每年的销售收入均在增长; Step 7:长期负债与权益的比值小于行业平均水平; Step 8:在纽约证券交易所、美国证券交易所以及纳斯达克上市的股票中市值排名前 75% 的个股。 |
| 米伦坎普 | Step 1:ROE 高于行业平均水平; Step 2:过去 5 年 ROE 的平均值高于行业平均水平; Step 3:P/E 小于行业平均水平; Step 4:P/B 小于 2; Step 5:过去 5 年 EPS 的平均值高于行业平均水平; Step 6:EPS 的年化复合增长率高于行业平均水平; Step 7:NPM 高于行业平均水平; Step 8:总负债与总资产的比值小于行业平均水平; Step 9:现金比率大于 1; Step 10:自由现金流为正。 |
| 聂夫 | Step 1:P/E 小于行业平均水平; Step 2:EPS 的增长率介于 2.7% ~ 20%; Step 3:PEG 小于 1; Step 4:过去 5 年每年的销售收入均有增长; Step 5:当年的 OPM 高于上一年的 OPM; Step 6:OPM 高于行业平均水平; Step 7:过去 3 年每年的每股自由现金流均在增长。 |
| 奥肖内西(成长) | Step 1:标普 1500 指数中,市值排名前 25% 的个股; Step 2:P/S 小于 1.5; Step 3:EPS 的增长率大于 0; Step 4:过去 5 年的 EPS 增长率高于标普 500 指数; Step 5:P/E 小于行业平均水平; Step 6:26 周的 RSI 为正; Step 7:在剩余的股票中,52 周的 RSI 最大的个股。 |
| 奥肖内西(价值) | Step 1:在纽约证券交易所、美国证券交易所以及纳斯达克上市的股票中市值排名前 50% 的个股; Step 2:P/E 小于行业平均水平; Step 3:股价与现金流的比值小于行业平均水平; Step 4:销售收入超过行业平均水平的 1.5 倍; Step 5:P/S 小于 1.25; Step 6:D/P 高于标普 500 指数; Step 7:EPS 的增长率介于 0 ~ 50%; Step 8:所发行的股份数高于数据集中股票所发行的股份数的平均水平; Step 9:剔除公用事业的股票后,D/P 在剩余的股票中最高。 |
| 皮奥特洛斯基 | Step 1:在 NYSE、NASDAQ 上市的股票中 P/B 排名最低 30% 的个股; Step 2:ROA 为正; Step 3:D/E 小于 1; Step 4:上一年长期负债与权益的比值小于两年前长期负债与权益的比值; Step 5:当年 NPM 高于上一年 NPM; Step 6:经营活动产生的现金流高于净利润; Step 7:当年的现金比率高于上一年的现金比率; Step 8:当年现金与流动负债的比值高于上一年现金与流动负债的比值; Step 9:销售收入与总资产的比值高于行业平均水平; Step 10:在纽约证券交易所、美国证券交易所以及纳斯达克上市的股票中市值排名前 30% 的个股。 |
| 邓普顿 | Step 1:在 Compustat 数据库中 P/B 最低的 40% 的个股; Step 2:P/E 小于过去 5 年的平均 P/E; Step 3:过去 12 个月以及过去 5 年盈利的增长率均为正; Step 4:EPS 的增长率高于行业平均水平; Step 5:OPM 高于过去 5 年的平均 OPM; Step 6:长期负债与权益的比值小于行业平均水平; Step 7:总资产与总负债的比值高于行业平均水平; Step 8:ROE 高于行业平均水平。 |
3.4 基于经典投资策略的股票筛选方法
| 股票大师 | 股票筛选方法 |
|---|---|
| 分析师上调评级 | 选择过去一个月分析师评级上调最多的 50 只股票。 |
| 道琼斯指数狗股 | Step 1:剔除所有非道琼斯工业平均指数中的公司; Step 2:在道琼斯工业指数中,D/P 最高的 33% 的个股。 |
| 盈利动量 | Step 1:过去 5 年 EPS 的增长率为正; Step 2:过去 5 年,EPS 的增长率排名位于前 20% 的个股; Step 3:下一年的预期 EPS 增长率高于过去 5 年的 EPS 增长率。 |
| 盈利修正 | Step 1:根据 IBES 数据库,选择过去 2 个月内,对下一年预期 EPS 的修正率最高的公司; Step 2:选择过去 5 年中 EPS 的增长率最高的 20% 的个股; Step 3:EPS 的增长率高于行业平均水平; Step 4:选择那些盈利惊喜最大的公司。 |
| GARP | Step 1:PEG 小于或等于 1; Step 2:过去 5 年的 EPS 增长率高于标普 500 指数; Step 3:过去 3 年的 EPS 增长率高于行业平均水平; Step 4:总负债与总资产的比值小于行业平均水平; Step 5:D/E 小于 1。 |
| 被忽视的公司 | Step 1:跟踪该股票的分析师人数不超过 2; Step 2:EPS 的年化复合增长率高于行业平均水平; Step 3:P/E 低于行业平均水平; Step 4:NPM 高于行业平均水平; Step 5:P/B 小于或等于 3; Step 6:过去 5 年的平均 ROE 高于行业平均水平; Step 7:在纽约证券交易所、美国证券交易所以及纳斯达克上市的股票中市值排名前 75% 的个股。 |
其中:
- D/E:债务股本比
- D/P:股利率
- EPS:每股盈利
- GPM:毛利率
- NPM:净利率
- OPM:营业利润率
- P/B:市净率
- P/E:市盈率
- PEG:市盈率与盈利增长率之比
- ROE:股权收益率
- RSI:相对强弱指标
4. 同步法
4.1 同步法的含义
筛选股票更为合理的方法是多因子同步筛选法。在同步法中,我们同时使用所有的选股标准对股票池进行评估,再根据选股标准的评估总分,对股票池中的所有股票进行排序。
4.2 同步法的理解
同步法的观点是:一只股票在某个标准上的劣势,可以由其在另一个标准上的优势来弥补。
因此,同步法类似高考。它不设“及格线”,而是给股票在每个标准上的表现打分,然后加总总分,再根据总分进行排名和选择。
4.3 标准化与Z值
在使用同步法筛选股票的时候,因为我们要一次性对所有股票完成因子筛选,所以一个必须要解决的问题是:如何解决不同因子单位尺度不同的问题?
直接将所有因子的值加总并不可行的,例如将市盈率因子和市值因子而言,将市盈率20和市值340,000,000相加没有任何意义,因为这样得到的结果永远由量级更大的市值因子决定。
处理因子加总问题的正确方法是将因子标准化或正态化,通过将变量转换为标准的度量单位,使得因子之间可以相互比较,而最常用的标准化方法是 Z 值法(Z-score method)。
4.4 Z值
4.4.1 Z值的定义与含义
对于某个因子(例如市盈率、动量、ROE 等),假设在某一期(例如某一天或某个月)我们有只股票,其因子值为:
首先来计算该因子的横截面均值和标准差:
均值为:
标准差为:
然后对每一只股票计算Z分数:
通过计算Z分数,我们可以得到观测值距离总体均值(市场平均水平)多少个标准差:
- Z = 0 表示与市场平均水平相当;
- Z = +1.5 表示比平均水平高 1.5 个标准差,属于非常优秀;
- Z = -0.8 表示比平均水平低 0.8 个标准差,相对较差;
同时,Z分数还将因子变为均值为0,标准差为1的分布(范围约为−3到3),解决了尺度不统一的问题。
4.4.2 Z值的几点补充说明
(1)正态分布
如果原变量服从正态分布:
则计算出的Z值:
服从标准正态分布:
此时Z值分布不仅符合均值为0,标准差为1,分布还满足以下概率:
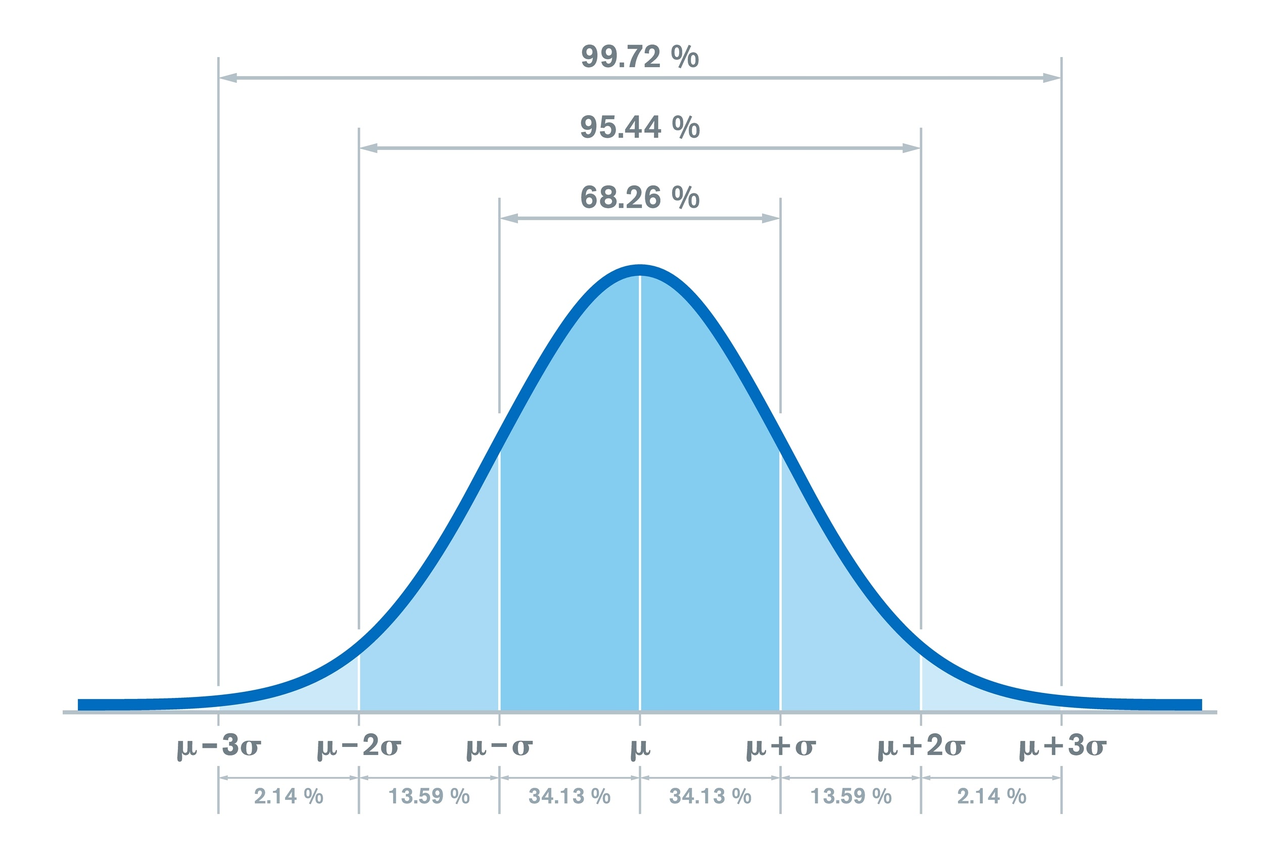
(2)极值处理
为了避免异常值(outlier)影响Z值计算结果,一般我们会设定某些控制机制。
例如,我们可以将所有大于3的Z值设为3,类似的,将所有小于-3的Z值设为-3。同样,我们也可以直接排除异常值,但是这样可能会损失那些潜在具有极高或极低收益率的股票的有用信息。
(3)Z值的正负
我们一般默认规定:高Z值代表好股票,低Z值代表坏股票。所以,若因子本身分布与期望结果相反,则应当将计算得到的Z值乘以-1。
例如,如果我们认为高市盈率的股票是好股票,则可以直接使用计算得到的Z值;如果我们认为低市盈率的股票是好股票,则需要得到的Z值乘以-1。
(4)中性化
如果我们选择的因子对行业十分敏感或是希望做到行业中性,那么我们在计算Z值时,会使用股票所属行业的均值而非整个股票池中的均值来计算。
4.5 加总Z值的方法
在得到所有股票在各个因子上的Z值之后,我们就可以通过同步法对股票进行筛选了,筛选主要有以下三种方法。
4.5.1 简单加总Z值
由于我们已经计算出了股票池中每只股票在各个因子上的Z值,而Z值又是尺度无关的,所以计算每只股票的Z值最简单的办法,就是直接将其全部因子的Z值加总,这样得到的股票Z值称为加总Z值(aggregate Z-score)。
这种方法的隐含观点是:我们对所有选出的因子一视同仁,赋予相同的权重。即:
在很多情况下,相对于那些更复杂的赋权方法,等权重赋权法可以得到更为稳定的结果。
4.5.2 先验加总Z值
先验加总Z值指的是根据我们事前的投资信念或投资风格来为因子赋权,俗称拍脑门。
例如,如果我们更偏好价值因子,那么为了凸显该因子的重要性,我们可以将该因子的权重设为60%,将其他因子的权重之和设为40%。
无论如何,根据对因子重要性的主观想法或偏好来为因子赋权均不是量化组合管理的方法,因此我们并不推荐先验加总Z值。
4.5.3 最优Z值加总
最优Z值加总是一种更为科学的优化简单加总Z值的方法,其主要思想是通过历史样本与计量经济学的方法来估计因子的最优权重,从而找到因子的最优赋权(optimal weighting)。
我们回归的基本公式为:
其中:
- :常数项;
- :因子k的Z值对股票收益率的估计值;
- :残差项;
虽然理论上最优Z值加总可以得到最佳权重,但由于估计误差、样本稳定性、过拟合等问题的存在,最优Z值加总并不一定能有更好的表现。
4.6 加总Z值与期望收益率
4.6.1 基本预测模型
同步法的基本预测模型为:
其中:
- :股票在时期的收益率;
- :股票在上一期()的综合因子 Z 值(因子暴露);
- :时期的横截面平均收益;
- :回归系数,表示因子收益率;
- :误差项,捕捉未被该因子解释的个体特异性收益。
这里的回归是在每一期的股票横截面上进行的。
4.6.2 预期收益公式
对回归模型取条件期望:
由于和在给定时是确定的,而误差项满足与解释变量不相关的假设:
所以有:
而市场平均收益为:
因此:
也就是说:预期超额收益 = 回归系数 × Z值。
4.6.3 回归系数的推导
简单线性回归满足:
写成标准差的形式为:
其中:
- :相关系数;
- :收益率标准差;
- :Z值标准差。
由于Z分数之前已经被标准化:
因此:
这里的在量化投资中被称为:IC(Information Coefficient)。
所以得到:
4.6.4 经验公式
将
代入之前的
得到:
这就是经验公式:预期超额收益=IC×收益率波动率×Z值
4.6.4.1 经验公式的理解 经验公式说明,一个股票的预测收益取决于三个变量:因子的预测能力(IC)、市场波动率()以及股票的信号强度()。
- IC 表示预测未来收益的准确程度。通常来说,常见因子的 IC 介于 0.02~0.05 之间,
IC < 0.01的因子属于弱因子,IC > 0.08的因子属于强因子。 - 表示市场波动率,如果市场波动很小,那么就算预测正确,收益也不会很大。
- 如前面所说,代表表示股票的信号强度(排序极端性)
经验公式之所以重要,是因为其揭示了所有横截面因子预测收益的本质结构,即:
4.6.5 经验公式与主动管理基本法则
对于量化股票投资的基本原则曾提到的主动管理基本法则:
可由经验公式推导得到,以下为推导过程:
回顾量化股票组合管理导论中提到的信息比率的定义:
对单只股票而言:
这意味着:如果我们只做一次博弈,我们的能力上限()完全取决于预测精度()和机会的强度()。
在现实中,我们显然不会仅仅投一只股票。假设我们有只相互独立的股票,且对每只股票都采取相同的信号强度并分配相等的权重。
此时,由于超额收益是线性加总的,如果有个独立的股票,总收益的预期值正比于:
同时,由于股票是相互独立的(相关性为 0),因此方差直接相加,标准差则按根号规律增长:
代入IR计算公式,得到: