组合权重
1. 前言
我们在之前已经学习了如何利用因子模型筛选股票。模型是区分“好”股票和“坏”股票的基本工具,然而,仅仅做到区分“好”股票和“坏”股票是不足以建立投资组合的。
我们不仅需要将一堆股票放进同一个篮子里,还需要确定组合中每只股票的相对权重,只有这样投资组合才是有意义的。
股票的赋权方法大致可以分为两类:不存在比较基准的情形和存在比较基准的情形。其中,不存在比较基准的情形包括先验法和方差-均值优化法两种具体方法,其中方差-均值优化法是更为常用的方法;存在比较基准的情形则包括先验法、分层抽样法、目标因子暴露法和跟踪误差最小化法四种方法,我们最为推荐跟踪误差最小化法。
我们下面依次来进行介绍。
2. 不存在比较基准的情形
2.1 先验法
先验法指那些不依赖复杂数学优化,而是基于直觉、简单规则或市场属性来确定权重的方法。主要包括等权重法、市值加权法和价格加权法等。
虽然先验法显然不是为股票赋权的最优方法,但通过学习先验法,我们可以先建立关于组合权重的基本直觉,为之后学习其他方法打下基础。
2.1.1 等权重法
等权重法 (Equal Weighting)是为股票分配权重最为简单直接的方法:为每只股票分配相等的权重。即:
只有当我们对组合中股票的信息(预期收益率、风险等)一无所知时,等权重法才会是合理的选择。
2.1.2 市值加权法
市值加权法 (Value Weighting)是根据股票市值的相对大小为股票赋权。这是目前主流指数(如沪深300、标普500)最常用的方法。
假设 代表第 只股票的市值,则股票 的权重为:
此外,市值加权法还有许多变体,比如使用市值的平方根来作为赋权依据,从而削弱超级大盘股的权重,防止组合过于集中在少数几家巨头身上:
但无论如何,和等权重法一样,市值加权法同样没有反映股票预期收益率和风险的信息,因此在能得到预期收益率和风险信息的情况下,不是我们为股票赋权的最优方法。
2.1.3 价格加权法
价格加权法 (Price Weighting)指的是对每一只股票买入同等的股数,因此价格越高的股票,在组合中占的金额比例(权重)就越大。
值得一提的是,道琼斯工业指数和日经225指数采用了价格加权法来编制指数,但之所以采用价格加权法,都是由于一些历史原因,我们在量化投资中极少使用该方法,因为股票价格往往受拆股等多种因素影响,并不代表公司的真实价值。
2.2 方差-均值优化法
2.2.1 基本思想
均值-方差优化(Mean-Variance Optimization, MVO)是一种相对先验法更优的赋权方法,其核心思想是:在给定风险下寻找最大预期收益,或在给定预期收益下寻找最小风险。
为了实现该思想,我们需要在给定的股票列表下,比较所有可能的股票组合。从理论上来看,我们可以通过股票收益率的方差和协方差来计算出各个组合的事前风险,通过也可以通过股票的预期收益率计算出各个组合的收益率,进而选择那个在相同预期收益率水平下风险最小的那个组合,或是相同风险水平下预期收益率最高的那个组合。
但是,由于存在无穷无尽的可能组合,所以计算每个可能组合的预期收益率和风险是很难完成的。因此,我们需要使用二次规划(Quadratic Programming)来寻找我们所需要的组合。
2.2.2 MVO 的约束
MVO 的一个明显缺点是:该方法会对一些异常股票(如风险非常低或收益率非常高的股票)赋予过大的权重。与此同时,在组合构建的过程中,股票收益率的均值和方法都是估计值,其中无可避免地会存在估计误差,我们很难衡量估计误差对异常值的影响大小。
为了缓解以上问题,我们一般需要在二次优化问题的基础上添加约束,例如设定股票权重的最大值、最小值或是卖空约束(权重不可为负)等。我们之后会通过几个常见约束作为示例说明。
但需要注意的是,我们应当只为 MVO 添加必要的约束,否则会造成无解的情况发生。
2.2.3 无约束 MVO
我们先来讨论当不加入约束条件的时候,如何使用 MVO。假设我们已经按照之前介绍的方法,得到了股票的收益率。
2.2.3.1 变量定义
首先,我们将股票收益率相关的信息以向量 以及矩阵 表示。其中 是股票收益率的 维列向量, 为股票池中股票的数量,矩阵 为股票收益率的 维方差-协方差矩阵。即:
其中, 为股票 的预期收益率, 为股票 收益率的方差, 为股票 和股票 收益率的协方差。
其次,一个投资组合可以由其权重向量 确定。 为股票权重的 维列向量:
其中, 为投资组合中股票 的权重。
进一步,若 为有效的权重向量,那么向量 的所有元素之和应该等于1(),我们定义 为 维全1列向量:
则有 。
2.2.3.2 二次优化
经过以上定义,我们得到由向量 所确定组合的预期收益率为 或 ,其风险(组合收益率的方差)为 或 。
因此,给定预期收益率 ,风险最小的组合为在具有约束条件 和 时,下列最小化问题的解:
注意到目标函数 是 的二次函数,同时约束条件是 的线性方程。数学上这类问题被称为二次优化问题,其对应的解法为二次规划。
对于上述约束,更常用的方法是使用如下方式来表示:
其中:
通过拉格朗日乘数法(Lagrange Multipliers),我们可以证明(证明过程略)以上问题存在解析解:
2.2.3.3 有效边界
在得到二次优化问题的解析解之后,我们通常的做法是:利用该方法,计算各种预期收益率水平下的最小风险,及该风险下的投资组合权重。
import numpy as np
import matplotlib.pyplot as plt
import scipy.optimize as sco
# ==========================================
# 第一步:生成模拟的市场数据
# ==========================================
np.random.seed(42) # 设定随机种子,确保每次结果一致
num_assets = 5 # 假设我们有5只股票
# 1. 模拟这5只股票的预期年化收益率 (在 5% 到 25% 之间)
mu = np.random.uniform(0.05, 0.25, num_assets)
# 2. 模拟协方差矩阵 (必须是对称且半正定的)
raw_mat = np.random.randn(num_assets, num_assets)
cov_matrix = np.dot(raw_mat, raw_mat.T) * 0.05 # 缩放一下波动率
# ==========================================
# 第二步:定义优化所需的计算函数
# ==========================================
# 计算组合波动率 (即目标函数,我们需要最小化它)
def portfolio_volatility(weights, cov):
# 对应公式: sqrt(w^T * Sigma * w)
return np.sqrt(np.dot(weights.T, np.dot(cov, weights)))
# 核心优化器:给定目标收益率,寻找最小波动率
def minimize_volatility_for_target(target_return, mu, cov):
num_assets = len(mu)
init_guess = np.ones(num_assets) / num_assets # 初始猜测:等权重
# 约束条件:
# 1. 权重之和必须为 1 (100% 仓位)
# 2. 组合预期收益率必须等于目标收益率 (w^T * mu = target_return)
constraints = (
{'type': 'eq', 'fun': lambda w: np.sum(w) - 1},
{'type': 'eq', 'fun': lambda w: np.dot(w, mu) - target_return}
)
# 注意:因为是“无约束”模型(允许卖空),我们在这里不设置 bounds (即不限制权重必须 >= 0)
result = sco.minimize(
portfolio_volatility,
init_guess,
args=(cov,),
method='SLSQP',
constraints=constraints
)
return result
# ==========================================
# 第三步:计算有效边界上的点
# ==========================================
# 我们设定一系列的目标收益率 (从低于最低收益,到高于最高收益)
target_returns = np.linspace(min(mu) - 0.10, max(mu) + 0.10, 100)
frontier_volatilities = []
for tr in target_returns:
opt_result = minimize_volatility_for_target(tr, mu, cov_matrix)
frontier_volatilities.append(opt_result.fun) # 记录在这个目标收益率下的最小波动率
我们以预期收益率为纵轴,风险(标准差)为横轴,将所有计算得到的结果绘制为一条曲线:
# ==========================================
# 第四步:数据可视化 (画图)
# ==========================================
plt.figure(figsize=(10, 6))
# 画出无约束边界曲线 (马科维茨子弹头)
plt.plot(frontier_volatilities, target_returns, 'b-', linewidth=2, label='Unconstrained Frontier (允许卖空)')
# 找出全局最小方差组合 (Global Minimum Variance Portfolio)
min_idx = np.argmin(frontier_volatilities)
plt.scatter(frontier_volatilities[min_idx], target_returns[min_idx], color='red', marker='*', s=200, label='Global Minimum Variance')
# 画出最初的5只模拟股票的位置
asset_vols = np.sqrt(np.diag(cov_matrix))
plt.scatter(asset_vols, mu, color='black', marker='o', s=50, label='Individual Assets')
# 设置图表格式
plt.title('Mean-Variance Optimization: Unconstrained Efficient Frontier', fontsize=14)
plt.xlabel('Volatility (Standard Deviation)', fontsize=12)
plt.ylabel('Expected Return', fontsize=12)
plt.legend(loc='best')
plt.grid(True, linestyle='--', alpha=0.7)
plt.show()
绘制结果:
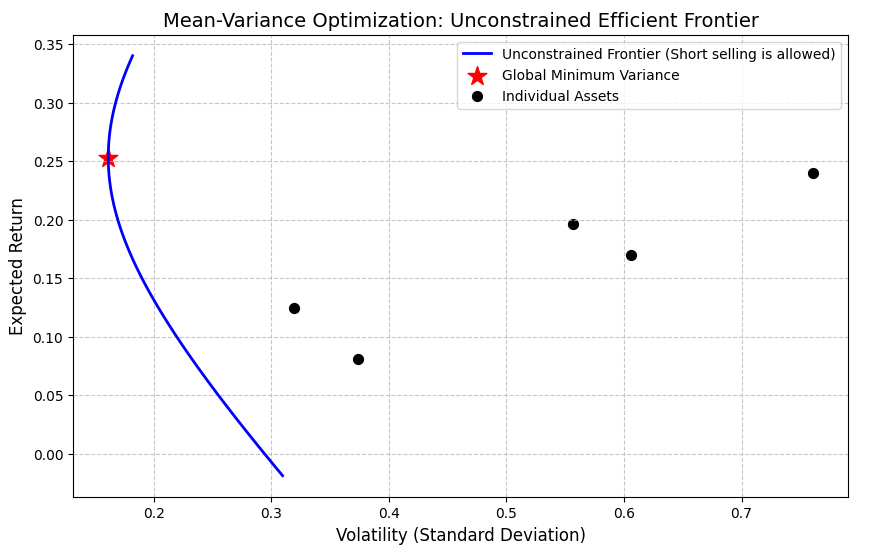
通过以上绘制结果,我们可以观察到以下现象:
(1)所有的黑点都被“包裹”在蓝线的右侧,没有任何一只单独的股票能落在蓝线上或蓝线左侧。
这是由于股票之间存在不完全的相关性(协方差),将它们组合在一起后,组合的整体风险(波动率)往往小于单只股票的风险。这就是我们常说的:“分散化是投资中唯一的免费午餐”。
(2)曲线可无限延展
投资组合的收益可以高于组合中收益率最高的股票,也可以低于组合中收益率最低的股票。
这是因为我们没有添加卖空约束,优化器此时会采取十分极端的策略:做空(赋予负权重)预期收益率低的股票,并加杠杆重仓(赋予超过100%的权重)预期收益率最高的股票。
这就是蓝线可以向上下两端无限延伸的原因,我们之后会看到添加了卖空约束的组合会发生怎样的变化。
(3)存在全局最小方差组合
我们绘制的曲线呈现抛物线的形状,存在最小方差的组合(红星标记处)。这意味着:即便我们买入全市场最安全的股票,也不如按照“红星”处的权重比例买入一揽子股票来得安全。
同时,红星将我们绘制的曲线分为了上下两部分。我们可以很容易想到,对于任何给定的风险水平,红星以上的曲线收益率都是最高的,而红星以下的部分则会在承担同样的风险的情况下,只拿到更低的收益。
因此,我们将红星以及红星以上的曲线部分称为有效边界或有效前沿(efficient frontier)。
2.2.4 有约束 MVO
我们接下来在无约束 MVO 的基础上,讨论各类常见的约束条件。
2.2.4.1 卖空约束
对于一个只能做多的组合来说,其面临的主要约束为卖空约束(short sales),即组合不能卖空证券。在数学上,我们可以用:
来表示卖空,即每只股票的权重至少为0。
虽然卖空约束的条件非常简单,但需要注意的是,此类不等式约束(inequality constraint) 会导致二次优化问题没有解析解,只能通过数值方法求得组合的最优权重。
假如限制卖空条件后,绘制新的组合曲线:
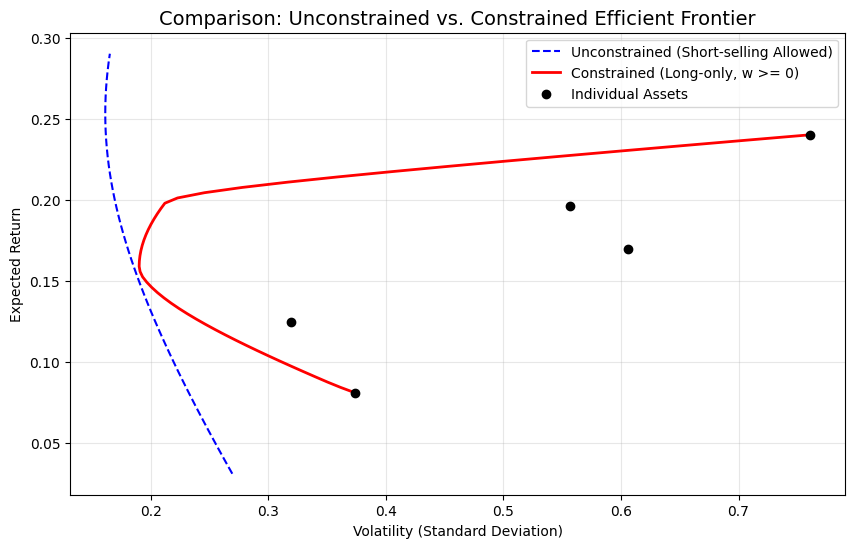
可以看到,此时组合(红线)的收益率范围被限制在了单只股票的最高收益率和最低收益率范围内,这是因为我们此时最多只能全仓买入收益率最高的股票。同时,含卖空约束的曲线(红线)始终在无约束曲线(蓝线)的右侧,这就是加入约束带来的效率损失。
2.2.4.2 分散化约束
有时候,我们希望限制组合过度重仓少数股票,以避免组合的非系统性风险,所以会加入分散化约束(diversification constraints):
其中 与 分别为股票所被允许的最小权重与最大权重的 维向量。
2.2.4.3 行业约束
另一个常见的约束是行业约束,我们希望将单一行业的股票限制在一定比例,其数学表达与分散化约束类似;
其中 表示行业 在组合中的权重。
2.2.4.4 交易额约束
当投资组合的规模大到一定程度时,投资组合的交易会对股票价格产生较大冲击,所以此时我们需要加入交易额约束,将股票持仓限制在一定阈值之内,以避免交易对价格产生不利影响。
假设投资组合的规模是5亿美元,我们想要将单只股票的持仓限制在股票平均交易额(ADV)的10%以内,以 表示股票 的权重, 表示股票 的平均交易额(单位为亿),那么交易额约束为:
一般地,交易额约束可以表示为;
其中, 为平均日交易额向量, 为常数,代表阈值。
2.2.5 风险调整后的预期收益率
到目前为止,我们都是以最小化风险的方式来表示均值-方差优化问题,这种思路适合于确定了具体收益率目标的情形。不过,如果我们设定的是具体的目标风险 ,那么使用预期收益率最大的表述方式会更加合适。即:
在 的条件下,求解:
此外,除了最大化收益和最小化风险,另一种十分实用的思路是引入风险厌恶系数 (risk aversion coefficient),从而将问题转化为了一个效用函数的最大化问题。
这里的风险厌恶系数 表示“我们为了多赚 1% 的收益,愿意多承担多少风险?”。例如,如果 的值为 2,意味着我们认为方差增加 1% 与收益率下降 2% 是等价的。
一旦确定了风险厌恶系数,MVO 问题即可变为:
我们可以看到,这里我们不再将风险作为约束项,而是作为“惩罚项”。而风险厌恶系数代表了我们面对该惩罚时的“胆量”。如果厌恶系很大,说明我们非常惧怕风险,此时权重会向低波动资产倾斜;反之则说明我们更看重收益,权重会向高收益资产倾斜。
3. 存在比较基准的情形
大多数组合的都会参照某一比较基准来管理组合,那些紧密跟踪比较基准的组合常被称为指数型投资组合(index portfolio),而那些不太紧密跟踪比较基准的组合则常被称为主动管理型投资组合(active portfolio)或指数增强型投资组合(enhanced index portfolio)。
因为我们所进行的是其中的主动管理(量化股票投资导论),所以我们的目标是:通过建立与比较基准大致相似的投资组合,来获得优于比较基准的业绩(即产生正)。在这个过程中,我们必须十分谨慎,因为我们需要严格控制比较基准的偏离程度。
对于此类存在比较基准的情形,常见的处理方法有先验法、分层抽样法、目标因子暴露法和跟踪误差最小化法,其中跟踪误差最小化法最为常用。
3.1 先验法
3.1.1 含义
要跟踪目标比较基准,最为直接的方法就是选择比较基准中市值最大的若干家公司,然后使用这些股票的相对市值计算股票权重,这有点类似我们前面提到的市值加权法。此外,我们可能还会进一步超配某些看好的股票以期获得超额收益。
3.1.2 步骤
实现以上先验法的途径有很多,我们这里以之前曾介绍过的 值法为例,说明使用先验法实现股票赋权的方法:
(1)确定偏离上限()
投资经理需要设定参数 。它代表允许单只股票的权重相对于市值加权权重的最大偏离幅度(例如不超过 2%)。
(2)标准化与寻找最大偏离点
假设我们已经为选到的市值最大的若干只股票计算好了标准化过 分数(均值为 0),则我们需要找到这些分数中绝对值最大的那个:
(3)计算缩放乘子()
为了保证计算出偏离程度不会超过第一步设定的上限 ,我们需要算出一个缩放系数:
(4)生成新权重
最终的权重 等于:
以上方法的巧妙之处在于:因为 (分数已经过标准化),所以:
这意味着我们不需要任何额外调整,新组合的权重之和天然为1。此外,通过限制 ,我们可以非常精准地控制自己距离基准的距离。如果将 设为 0,则组合就退化为了纯粹的指数基金。
3.1.3 评价
和之前关于先验法的说明一样,我们几乎可以肯定先验法并非最优的赋权方法,因为它本质上还是以市值为核心,对规模因子过于敏感,此外,它也没有试图去最小化跟踪误差。
总而言之,先验法并不能满足我们的需要。
3.2 分层抽样法
3.2.1 含义
分层抽样法是一种较为粗略的统计学处理方法,它的核心处理思路是把股票池按特定的属性(如行业、规模等)先“切块”,再从每个块里挑股票,从而使得我们可以从庞大的总体中抽取具有代表性的样本。
3.2.2 步骤
分层抽样法的大致思路为:
(1)定义分层维度
假设我们同时按“行业”(9个)和“规模”(3个:大、中、小)两个维度划分,这样就会产生9*3=27个互不重叠的小格子(切块)。
(2)确定每层的抽样比例
为了保证组合不偏离基准,每一层选取的股票数量应与该层在基准中的占比一致。假设:
- 为总股票池数量。
- 为第 层(小格子)中的股票数量。
- 为最终构建的组合中包含的股票目标总数。
则我们在第 层应该选取的股票数量为(结果四舍五入):
(3)在层内选股 在同一个格子(比如“金融行业+大市值”)里,我们根据 Z 值、预期收益率或风险调整后收益率等依据对股票进行排序,优先选取格子内排名靠前的 只股票。
3.2.3 评价
分层抽样法确实具有一定的优点,例如保证了组合在各个划分维度上都有分布。但是和先验法类似,它同样缺乏精确的风险控制:分层抽样法只控制了我们选取的“大类特征”(如行业),但无法控制细微风险。例如,分层抽样法能保证我们持有银行股,但无法保证这些银行股之间的相关性是否异常。
因此,分层抽样法也不是我们一般所使用的方法。
3.3 目标因子暴露法
3.3.1 含义
如果说分层抽样是“物理切块”,那么目标因子暴露法就是“数学对齐”。目标因子暴露法不要求组合里必须包含哪些行业的股票,而是要求组合整体的风格因子特征与基准指数保持一致,即:将比较基准的因子暴露设为组合的目标因子暴露。
3.3.2 因子倾斜
和之前介绍的 MVO 方法类似,我们在这里也会根据自身的判断,将组合中的各个因子暴露约束在某个特定范围,这有时被称为因子倾斜(factor tilting)。
例如,如果我们认为市场将迎来反弹,那么可能会希望组合相对于比较基准在市场贝塔上有更大的暴露,而在其他因子上的暴露则保持与比较基准相同。
3.3.3 处理方法
假设组合中有 只股票,其权重向量为 。同时我们有 个风格因子,第 只股票在第 个因子上的暴露为 。那么股票的因子暴露矩阵 (N × K)为:
组合在因子 上的总暴露 为:
通常,我们会为组合加入类似这样的因子暴露约束条件,来实现对因子的偏好:
3.4 跟踪误差最小化法
3.4.1 含义
对于大多数参照某一比较基准来管理的投资组合而言,最常用的组合构建方法是跟踪误差最小法。
这一方法的逻辑在于:我们通过设定组合与比较基准偏差的阈值,在不超过该阈值的前提下,使得组合的超额收益率最大化。这一偏差阈值就被称为跟踪误差。
3.4.2 跟踪误差
跟踪误差(tracking error,TE)一般被定义为组合收益率 减去比较基准收益率 的标准差,即:
一般来说,跟踪误差约束会被设定为年化0.5%~10%之间。
此外,为了简化计算,我们一般在量化中处理的是跟踪误差的平方——跟踪方差(Tracking Variance),即 。
3.4.3 跟踪误差的计算公式
我们在因子模型中曾介绍过,单只股票 的方差为:
假设各个股票残差之间的协方差为0, 股票的因子暴露矩阵为 (沿用3.3.3的定义),因子溢价的方差-协方差矩阵为 ,随机误差项方差的对角阵为 。
那么各个股票收益率之间的方差-协方差矩阵 可以表述为:
其中:
- 代表共同风险:这是由因子(如行业、规模、价值)引起的风险。
- 代表特有风险:这是单只股票“不合群”的波动(如某公司突然爆出丑闻)。
在以上定义的基础上,我们进一步设 为投资组合权重, 为比较基准权重, 为资产收益向量,则有:
因此组合收益率与基准收益率的偏离程度可以表示为:
代入跟踪方差的定义:
可以将跟踪方差转化为:
以上公式表明,根据误差同时由偏离度( )和联动性 ( )决定:如果我们偏离基准去买的那些股票本身波动很大,或者它们之间高度相关,那么跟踪误差就会上升。
通过跟踪方差的格式可以看到,这里和 MVO 问题一致,在我们添加各类约束之后,是一个二次优化问题,我们同样采用二次规划来求解。
3.4.4 风险调整后的预期收益率
和2.2.5节介绍过的内容类似,我们在这里也会不断尝试增加预期超额收益率,直至跟踪误差达到最大限制。
从数学上来讲,在不考虑其他约束条件的前提下,我们给定目标跟踪误差 ,在 的约束下,求解以下问题:
当然,我们也可以设定跟踪误差厌恶系数 ,将优化问题转化为: