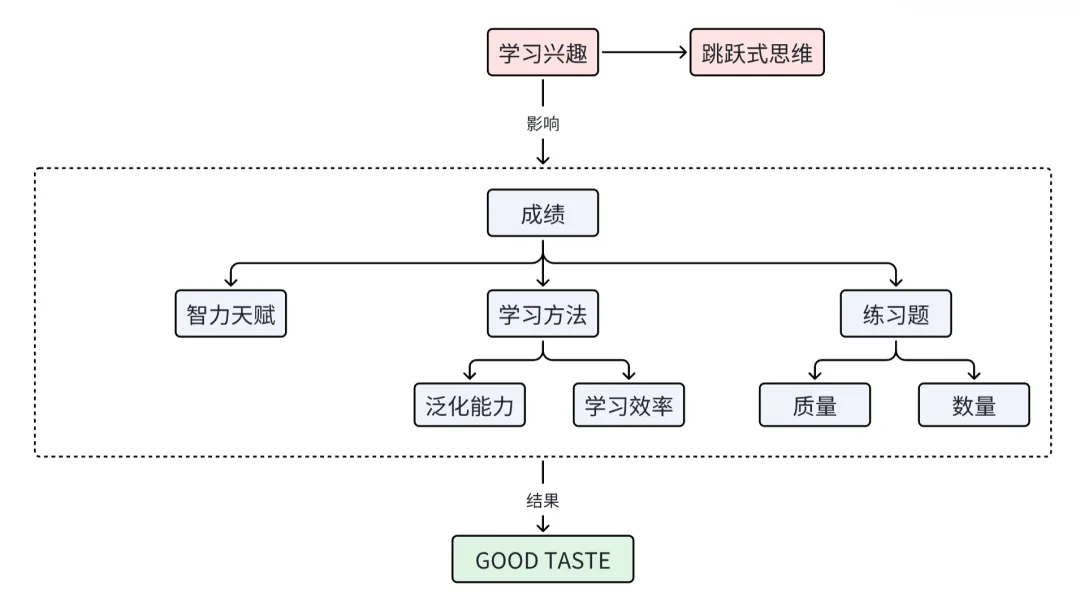
从“Good Job”到“Good Taste”:到底何为好的教育?
0 前言
从小到大,我的教育经历虽然说不上顶级,但在许多人看来都已经“相当不错”,无论是历城二中、厦大还是港大,都是别人(至少是本地人)听到会给我竖个大拇指的学校,我在其中也遇到了很多相当好的老师,他们在我各个阶段给予了我相当大的帮助。
但是,我始终隐隐地感觉,我接受的教育并没有达到我心中“理想的教育”的程度。虽然我不像《上交生存手册》那样,认为“国内绝大部分大学的本科教学,不是濒临崩溃,而是早已崩溃”,但我总觉得我得到的教育,并不能配得上我所付出的努力。
在很长时间里,我其实并不能很好地表达这样微妙的失望,所以只能把这种不满归咎于应试教育、念PPT的老师、绩点制度或是学校与社会的脱节。
转机发生在我开始学习国外的计算机公开课,从Harvard的CS50,到UC Berkeley的CS61A、CS61B,再到MIT的Crash Course,我终于开始明白我的失望来自于何处:原来自始至终,学校和老师所做的只是讲授知识,却从来没有想过如何能更好地让学生理解知识,更没有思考过如何培养学生学习的兴趣。
学习,本身就是一件很cool的事情。
1 点燃那把火
有一段时间,“快乐教育”的概念一度十分流行,但后来又被很多人指责为骗局。其实在我看来,“快乐教育”本身没有问题,只是很多人被欧美老师“Good job!”、“Well done!”、‘‘Amazing!’’等无数频繁而夸张地赞美误导,曲解了它的含义。
真正的“快乐教育”,从来不是规避掉考试、排名、批评等一切可能让学生感到挫败感的事物,让学生在学习中始终保持“快乐”。这实际上也是不可能的,因为求知的路上必然会伴随无数的失败、孤独和自我怀疑。
**真正的“快乐教育”,应该是用一切手段鼓励学生勇敢地提出自己的想法。**尽管这些想法可能相当幼稚,但这些幼稚的想法正是学生原始兴趣的体现,因为人只会主动地思考自己感兴趣的东西——能提出这些想法,就说明他们开始在主动地思考,而非被动地接受知识。
这些原始的兴趣就像种子,而老师需要做的就是保护这些种子,因为这些种子大多太过脆弱了,一点点质疑或是忽视就会扼杀这些种子,但如果这些种子能够发芽、成长,最终变成参天大树,彼时就没有任何东西再可以撼动其一丝一毫了,只有这些长成参天大树的种子,可以帮助他们穿越那无数的失败、孤独和自我怀疑,抵达知识的彼岸。
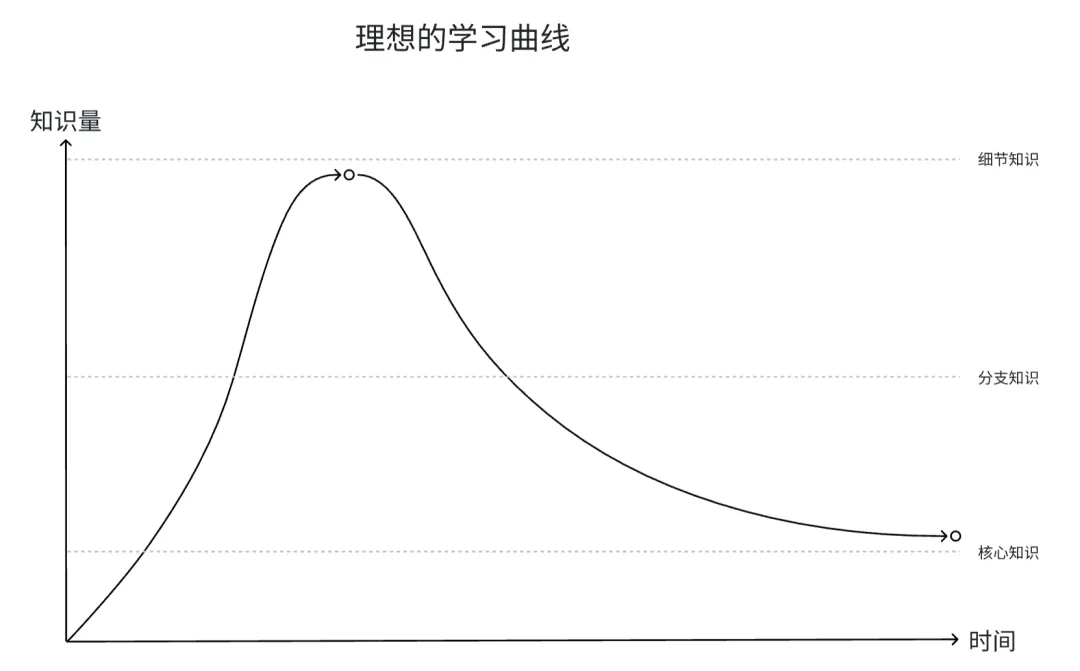
2 “知识降维”
激发学生的兴趣是教育最核心的任务,但从种子到大树,离不开中间的施水浇肥,这对应的也就是老师的最基础的本职工作——教授知识。
在理想的教育中,“如果有一个好的老师讲授一门好的课程,任何一个学生都能享受学习的过程”,但现实的情况来看,绝大多数的老师在这一点上做的也不够好,学生能不厌学或是患上抑郁之类的心理疾病,就已经算是谢天谢地了。
单从传授知识角度来看,一个“好老师”和一个“差老师”的区别究竟在哪里呢?核心就在于老师是否能帮助学生实现“知识降维”。
“知识降维”是类比数据分析领域“数据降维”所表达的一个概念,“数据降维”指的是简化高维数据并尽量保留原始数据的主要信息。
以数据降维中最基础的“主成分分析”(Principal Component Analysis,PCA)方法为例,我们用下面的图表来直观感受数据是如何实现降维的:
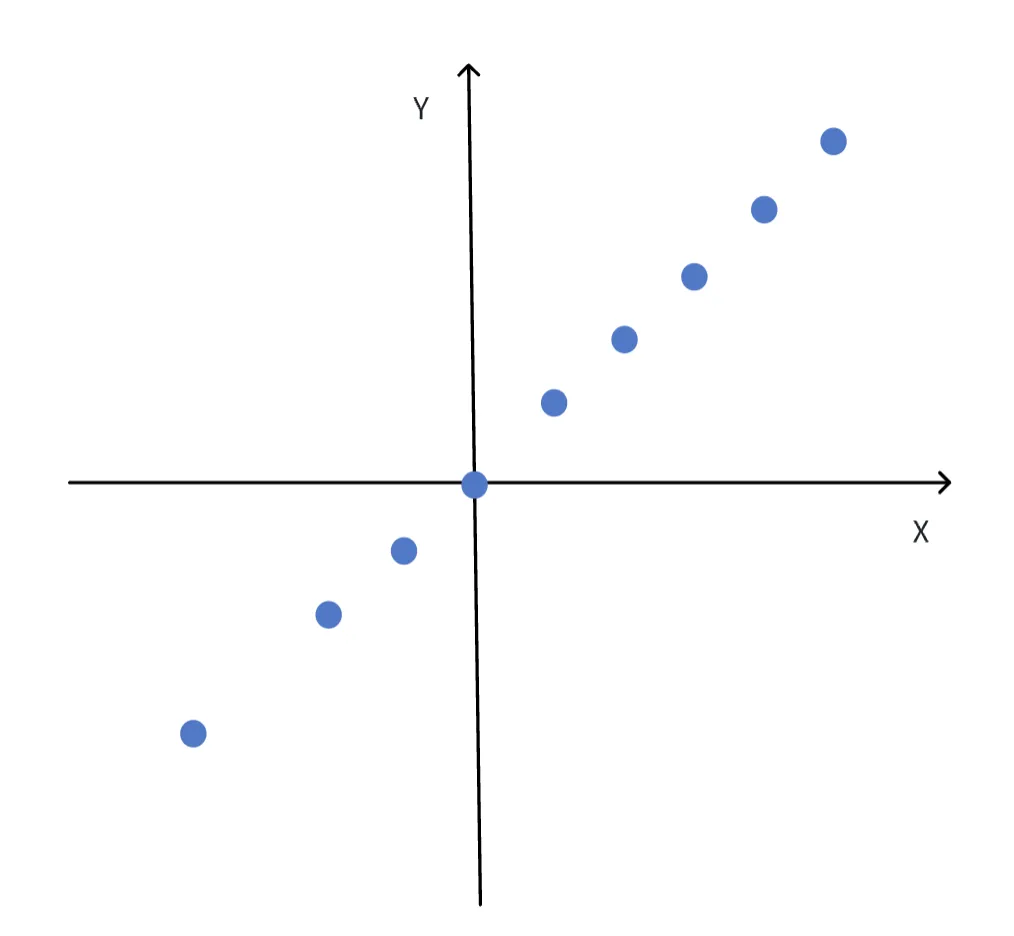
在上面的坐标系中,每个蓝色圆点的位置都有两个参数:横坐标x和纵坐标y组成,是一个二维的数据。我们如果想要存储所有的圆点位置数据,就需要同时记忆所有圆点的横坐标和纵坐标。
但是,我们观察到,似乎所有的蓝色圆点的横纵坐标都近似符合y=x这一规律。因此,我们可以通过旋转坐标系,将数据降维为一维数据:
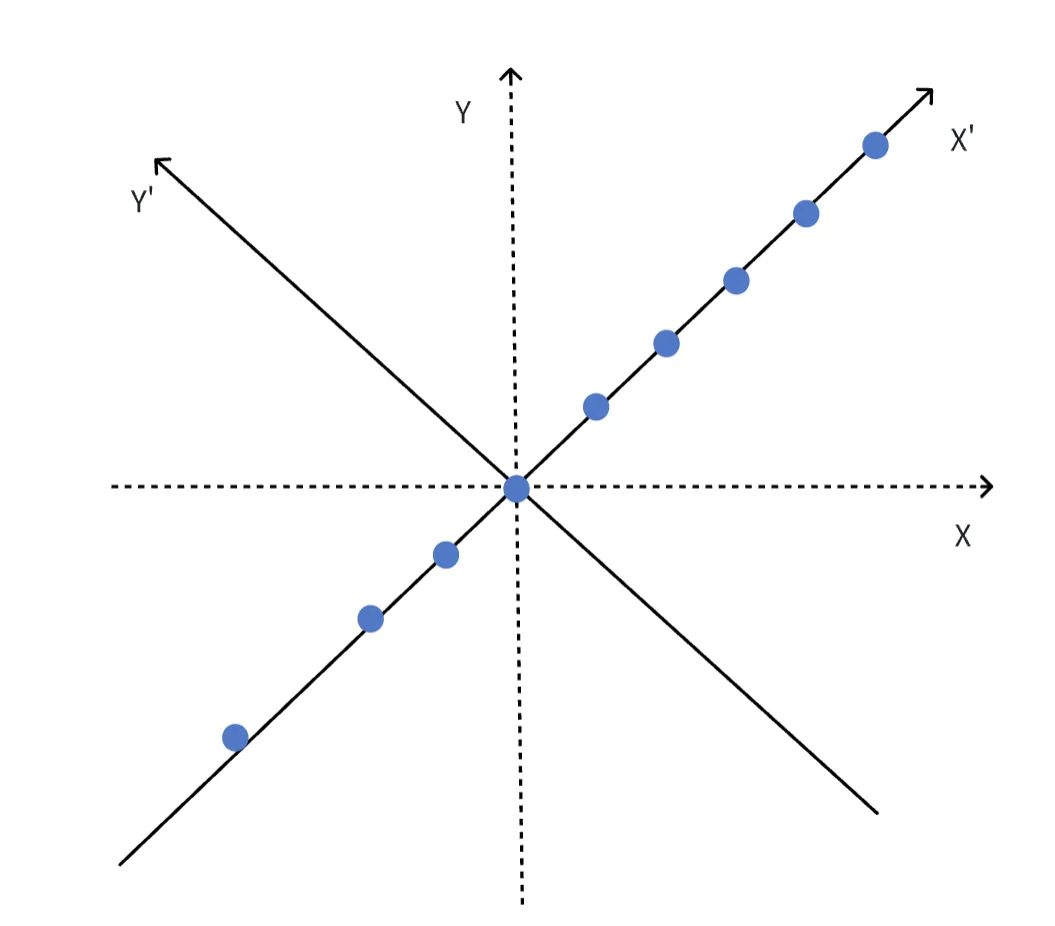
此时,所有圆点的纵坐标都变为0,我们只需要记忆所有圆点的横坐标x,即可存储所有圆点的位置。此时,我们在几乎没有损失任何信息量的情况下,直接减少了一半需要记忆的数据量。
老师所谓的“将知识嚼碎了喂给学生”,就是应该对全部的知识进行类似的预处理,将高维的、复杂的知识降维为低维,让学生从纷繁复杂的知识中了解最核心、最本质的内容,也就是所谓的“元知识”。
这些“元知识”就像树的树干,学生从树干出发,到达代表各个细分领域的树枝,最后再到代表各种细节的树叶,最终拥有了知识的整体框架,理解各个知识之间的内在联系,而非迷失在无数的细节中。
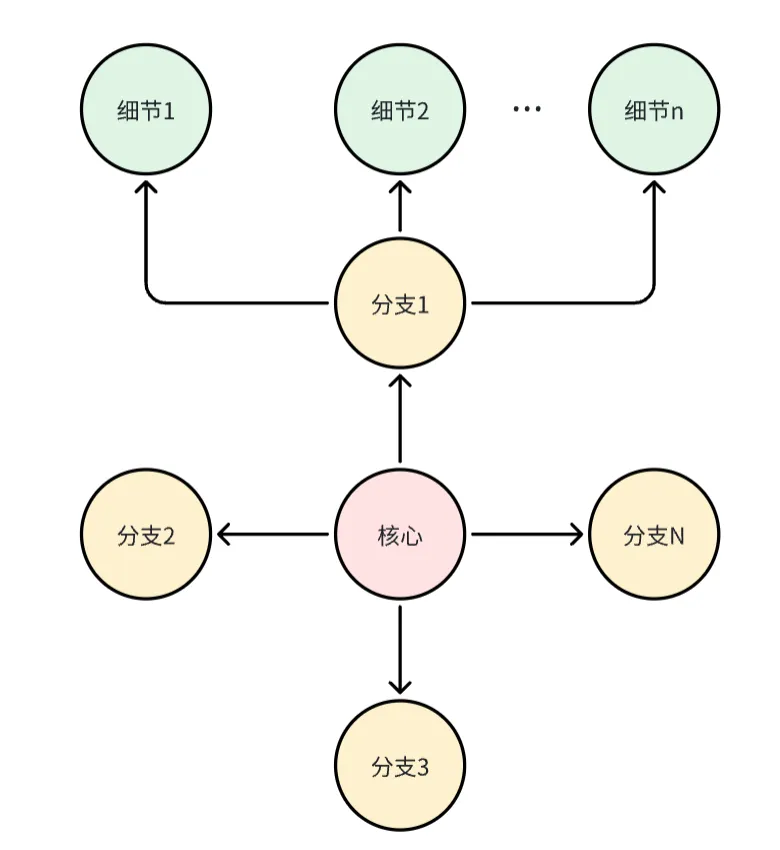
就像律师不可能背过全部的法条、会计师不可能背过所有的会计准则、医生也不可能记住关于人体的所有知识点,学习的目的从来不是让自己成为人形教科书,记住所有的知识点,而是拥有对这门学科的深刻理解,而理解的背后,就是知识的框架感。那些细节或许会随着时间推移,逐渐过时、被遗忘,但知识的核心框架体系可以一直存在。
说句题外话,在所有AI大模型的名字里,DEEPSEEK是我最喜欢的一个。因为我觉得这个名字特别好地说明了学习的本质。到底什么是“deep seek(深度求索)呢”?为什么要“深度”求索呢?“shallow seek(浅度求索)”不可以吗?从模型的角度,所谓的“深度”就是让AI像人一样,去深入知识的核心与本质,而非浮于大量的细节。
讽刺的是,当如今AI已经开始深入进行深度思考之时,无数的人却从未有过深度思考的能力,这正是因为,现实中的大多数老师,既没有将知识降维、分层的意识,也没有相应的能力,他们扮演的只是知识的复读机。
到这里,我们可以更完整地回答前面的问题了:在传授知识的层面,“好老师”和“差老师”的差别究竟在哪里?
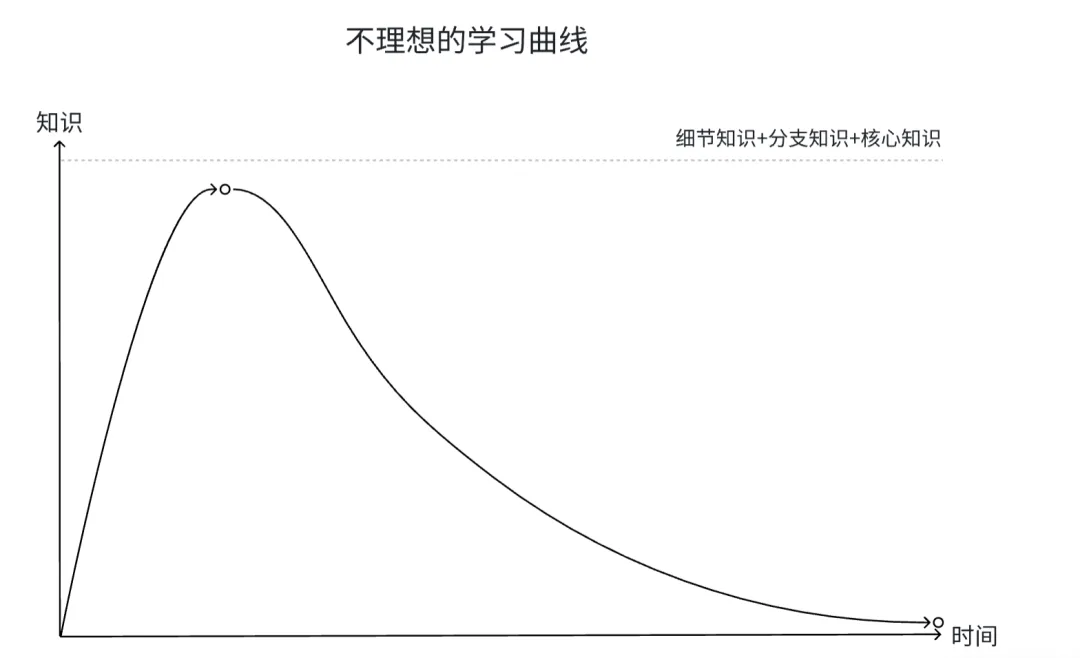
答案是:“好老师”可以通过对知识以及相应练习的预处理,让学生事倍功半地花费最小的训练成本拥有对知识体系的理解,而“差老师”只是将全部的知识一股脑地灌输给学生,再丢给学生海量而低质量的练习题,学生只能自己摸索其中的规律。
毫无疑问,在这样的模式下,绝大多数的学生只会迷失在无穷无尽的垃圾习题中,而这,就是当下无数衡水中学拙劣模仿者的现状。
3 学习的三要素
再进一步,让我们将视角从老师切换为学生,我们都知道有无数变量影响着学生的成绩,老师好坏、家庭环境、学校学习氛围……但决定一个学生成绩的核心因素究竟是什么呢?或许我们可以从AI的训练中得到答案。
我们一般认为,**算力、算法和数据是构建和训练大模型的三大核心要素。**其中,算力提供基础设施,决定了模型训练的规模和速度;算法决定了模型如何高效学习和利用数据;数据则为模型提供了学习的基础内容。
算力、算法和数据这三者缺一不可。例如,缺乏高质量数据,即使有强大算力和先进算法,模型也可能过拟合或表现不佳;同样,算法不佳可能导致算力浪费或模型性能低下。
而对应到人类的学习,算力、算法和数据即分别对应人的智力水平、学习方法和练习题。
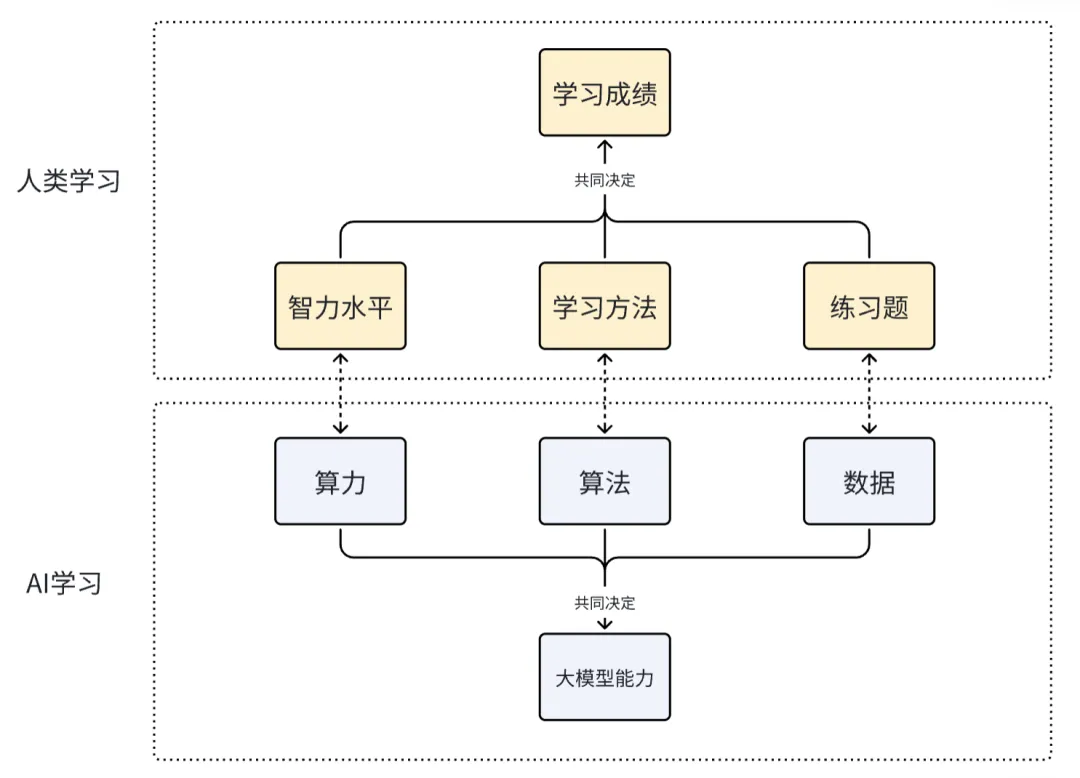
具体来说:
(1)算力 ≈ 人的智力水平
算力类似于人类智力的“计算能力”或“认知能力”,在其他条件不变的前提下,智力水平高的人会在处理复杂问题、推理或记忆时更高效。
比如,而大部分人八岁的时候只能算100以内的加减法,而冯·诺依曼在八岁时就精通微积分了,这就是人脑这台“计算机”的算力不同导致的——有的人生来就是32G显存的5090,有人的吃再多聪明药也是古董机的集显,碰上复杂的项目运行都运行不了。
(2)算法 ≈ 学习方法
算法可以看作是人类的“学习方法”或“思维策略”。比如,我们通过归纳、演绎、类比等方法来学习,而大模型通过优化算法(如梯度下降、注意力机制)来调整参数,找到数据中的规律。
好的学习方法能让我们更高效地从练习题中学习知识,总结其中的规律。这也就是前面“知识降维”的含义,如果老师可以帮助学生来优化“学习算法”,那么就可以提高学生的学习效率。
(3)数据 ≈ 练习题
数据是大模型的“学习材料”,就像练习题是人类学习知识和技能的素材。通过大量练习(数据),模型或人可以从中提取规律、提升能力。高质量的练习题(干净、结构化的数据)能让学习更有效,而低质量或错误的练习题(噪声数据)可能导致错误或偏见。
到这样,我们也就可以揭示学习的本质了:学习是一个从资源(算力/智力水平)、方法(算法/学习策略)和素材(数据/经验)协同作用的过程。其中智力水平与生俱来,因此,学生想要得到更好的成绩,就必须优化学习方法,同时获得充足且高质量的练习题。
4 泛化能力
记得在我上学的时候,曾经有一个经久不衰的讨论:“题海战术究竟有没有用?”
当时许多老师给出的结论是:有用,但效果十分有限,所以不建议使用。
他们给出这个结论的依据是他们过往的教学经验,但在今天人工智能的时代,这个答案得到了更好的印证,因为我们有了一个真正意义上执行“题海战术”的学生——AI大模型。
实际上,学生所执行的“题海战术”,其实并不能称作真正的“题海战术”。简单来算一笔账:高中三年一共约1000天,假设每个学科每三天做一套试卷,那么一个学科三年下来其实也就做了300多套。如果学生特别能学,每两天做一套,那也就能做500套,数量级上并没有显著的差异。如果考虑到各种校园活动、生病等因素,那么这个差距还会更小。
而对于AI大模型,只要是市面上能够搜索到的题目,无论在不在考试范围中,它都做过。不仅如此,它还有着无数强大的buff——可以一目十行(或者应该说是万行)/永远认真,从不偷懒/从不粗心/不会生病、失恋、和朋友闹矛盾,永远保持最佳状态……
这些buff随便挑一个给学生,不考个985都说不过去,但把所有这些buff给AI叠在一起,即使是现在最强的AI的成绩也无法超越前5%的学生,这是为什么呢?
原因在于,AI不具备人类对知识的泛化能力。人类能通过极少量的经验进行泛化,得到良好的学习结果,而大模型即使是通过大几个数量级的数据训练,也无法达到类似的效果。
实际上,这就是我们常说的学习要“举一反三”。学生在学习的时候只有不断思考、反思,优化自己的学习方法,才能通过更少的训练量达到同样乃至更好的学习效果。
反过来说,这也是“题海战术”从根本上低效的原因,因为“题海战术”意味着放弃对自己学习方法的优化,而只是一味的通过增加训练量来提升成绩,而AI的成绩,就是这种方法的理论上限。
5 跳跃式思维
除了泛化能力,人类相比于AI的另一个重大优势是人类拥有跳跃式思维(或称为发散性思维、联想思维)。
人类的思维不是严格线性的,可以从一个想法跳到另一个看似不相关的想法,这种跳出固有思维框架的能力在发现跨学科、跨领域的隐秘联系,以及激发创造性火花方面发挥了重要作用。
例如,爱因斯坦从牛顿力学和麦克斯韦电磁学中找到灵感,提出了相对论;达·芬奇将解剖学与工程学结合,设计了飞行器。这种跨领域的“火花”往往源于直觉、类比或偶然的灵感。
相比之下,AI的“学习”主要基于训练数据的统计规律,倾向于在已有模式内进行推理,它并不具备主动探索未知领域的能力,因此很难像人类一样“无中生有”地创造新连接,除非数据中已包含类似关联。
换言之,AI的推理过程是由用户输入或训练目标驱动所被动触发的,而非人类那种自发的、基于好奇心的“跳跃”冲动,而这,这也再次体现了前面提到的激发学生兴趣的重要性。
6 “GOOD TASTE”
我在上中学的时候,考完试经常听到旁边某个学霸聊试题的时候,会略显轻蔑的说“这套题质量一般~”。虽然这么说稍微有点装,但现在看来,如果能说出这句话,就说明学生已经完全理解并消化吸收了所学知识,知道了什么样的试题是所谓的“好的试题”,而这,就是拥有了对知识所谓的“GOOD TASTE”(好的品味)。
“GOOD TASTE”是CS中的一个约定俗成的说法,它表达的是程序员编写代码或review他人代码时体现出的风格——能用优雅、简洁和高效的代码完成功能,就不应该用臃肿、复杂和低效的方式实现。就像同样在米其林餐厅吃饭,美食家可以尝出饭菜究竟好在哪里,而大多数人只是猪八戒吃人参果,全然不知滋味。
同时,“GOOD TASTE”不只代表了对已有知识的深刻掌握,它更代表了一种识别知识“质量”的能力,这种能力会更为深远地影响学生之后的人生。
在如今这个信息爆炸的时代,人们可以获取到海量的知识,但人的时间和精力总是有限的,“吾生也有涯,而知也无涯 。以有涯随无涯,殆已!”。更何况,其中绝大多数知识的质量都极低,甚至可以说是“垃圾知识”,如果没有识别知识“质量”的能力,那么人们只会被淹没在无穷无尽垃圾之中。
尾声:理想教育
最后,我想引用CSDIY中北大飞猪(PKUFlyingPig)的一段话作为结尾,飞猪写下这段话是2021年,今年是2025年,而实现让“曾经的遗憾和痛苦永远成为历史”要到哪一天呢?我也不知道。但我相信,风不会一直向西吹,我也和很多人一样,期待着那一天的到来。

附录:文章结构